1. Introduction
We all know that data entered in the tables are persisted in the physical drive in the form of database files. Think about a table, sayCustomer (For
any leading bank India), that has around 16 million records. When we
try to retrieve records for two or three customers based on their
customer id, all 16 million records are taken and comparison is made to
get a match on the supplied customer ids. Think about how much time that
will take if it is a web application and there are 25 to 30 customers
that want to access their data through internet. Does the database
server do 16 million x 30 searches? The answer is no because all modern
databases use the concept of index. 2. What is an Index
Index is a database object, which can be created on one
or more columns (16 Max column combination). When creating the index
will read the column(s) and forms a relevant data structure to minimize
the number of data comparisons. The index will improve the performance
of data retrieval and adds some overhead on data modification such as
create, delete and modify. So it depends on how much data retrieval can
be performed on table versus how much of DML (Insert, Delete and Update) operations. In this article, we will see creating the
Index. The
below two sections are taken from my previous article as it is required
here. If your database has changes for the next two sections, you can
directly go to section 5. 3. First Create Two Tables
To explain these constraints, we need two tables. First, let us create these tables. Run the below scripts to create the tables. Copy paste the code on the new Query Editor window, then execute it.CREATE TABLE Student(StudId smallint, StudName varchar(50), Class tinyint);
CREATE TABLE TotalMarks(StudentId smallint, TotalMarks smallint);
Go
Note that there are no constraints at present on these tables. We will add the constraints one by one. 4. Primary Key Constraint
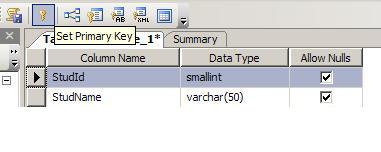
A table column with this constraint is called as the key column for the table. This constraint helps the table to make sure that the value is not repeated and also nonull entries. We will mark the StudId column of the Student table as primary key. Follow these steps: - Right click the
studenttable and click on the modify button. - From the displayed layout,
selecttheStudIdrow by clicking the Small Square like button on the left side of the row. - Click on the Set Primary Key toolbar button to set the
StudIdcolumn as primary key column.
Now this column does not allow
null values and duplicate
values. You can try inserting values to violate these conditions and
see what happens. A table can have only one Primary key. Multiple
columns can participate on the primary key column. Then, the uniqueness
is considered among all the participant columns by combining their
values. 5. Clustered Index
The primary key created for theStudId column will create a clustered index for the Studid column. A table can have only one clustered index on it. When creating the clustered index, SQL server 2005 reads the
Studid column and forms a Binary tree on it. This binary tree information is then stored separately in the disc. Expand the table Student and then expand the Indexes. You will see the following index created for you when the primary key is created: studid decreases the number of comparisons to a large amount. Let us assume that you had entered the following data in the table student: 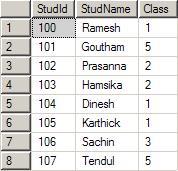 The
The index will form the below specified binary tree. Note that for a given parent, there are only one or two Childs.
The left side will always have a lesser value and the right side will
always have a greater value when compared to parent. The tree can be
constructed in the reverse way also. That is, left side higher and right
side lower. 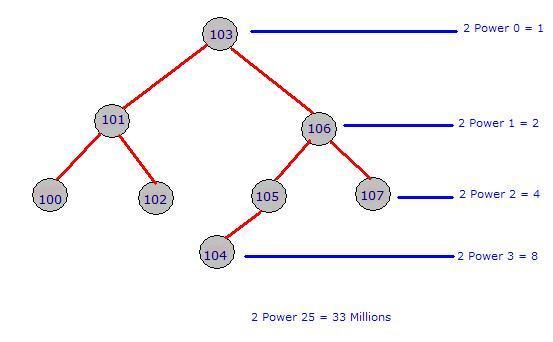 Now let us assume that we had written a query like below:
Now let us assume that we had written a query like below:Select * from student where studid = 103;
Select * from student where studid = 107;
Execution without index will return value for the first query after third comparison.Execution without index will return value for the second query at eights comparison.
Execution of first query with index will return value at first comparison.
Execution of second query with index will return the value at the third comparison. Look below:
- Compare 107 vs 103 : Move to right node
- Compare 107 vs 106 : Move to right node
- Compare 107 vs 107 : Matched, return the record
YahooLogin. Let us assume there are 33 million users around the world that have Yahoo email id and that is stored in the YahooLogin.
When a user logs in by giving the user name and password, the
comparison required is 1 to 25, with the binary tree that is clustered
index. Look at the above picture and guess yourself how fast you will reach into the level 25. Without Clustered index, the comparison required is 1 to 33 millions.
Got the usage of Clustered index? Let us move to Non-Clustered index.
6. Non Clustered Index
A non-clustered index is useful for columns that have some repeated values. Say for example,AccountType column
of a bank database may have 10 million rows. But, the distinct values
of account type may be 10-15. A clustered index is automatically created
when we create the primary key for the table. We need to take care of
the creation of the non-clustered index. Follow the steps below to create a Non-clustered index on our table
Student based on the column class. - After expanding the
Studenttable, right click on theIndexes. And click on the New Index.
- From the displayed dialog, type the index name as shown below and
then click on the Add button to select the column(s) that participate in
the index. Make sure the
Indextype is Non-Clustered.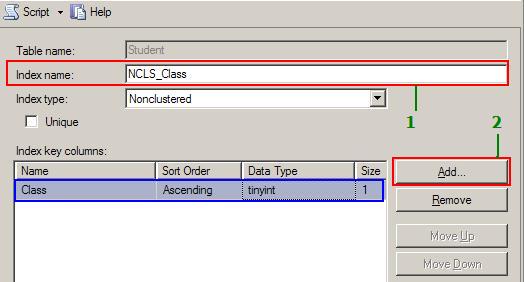
- In the select column dialog, place a check mark for the column
class. This tells that we need a non-clustered index for the column
Student.Class. You can also combine more than one column to create theIndex. Once the column is selected, click on the OK button. You will return the dialog shown above with the selected column marked in blue. Our index has only one column. If you selected more than one column, using theMoveUpandMoveDownbutton, you can change order of the indexed columns. When you are using the combination of columns, always use the highly repeated column first and more unique columns down in the list. For example, let use assume the correct order for creating the Non-clustered index is:Class,DateOfBirth,PlaceOfBirth.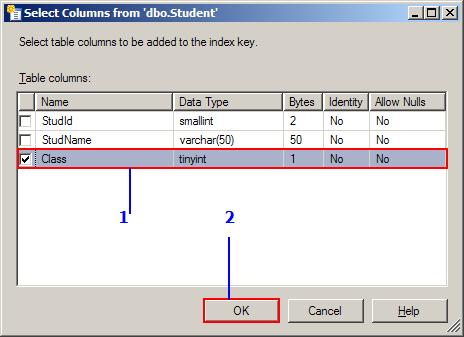
- Click on the Index folder on the right side and you will see the non-clustered index based on the column class is created for you.
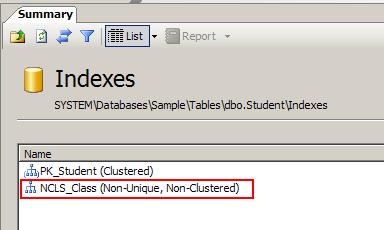
7. How Does a Non-Clustered Index Work?
A table can have more than one Non-Clustered index. But, it should have only one clustered index that works based on the Binary tree concept. Non-Clustered column always depends on the Clustered column on the database.This can be easily explained with the concept of a book and its index page at the end. Let us assume that you are going to a bookshop and found a big 1500 pages of C# book that says all about C#. When you glanced at the book, it has all beautiful color pages and shiny papers. But, that is not only the eligibility for a good book right? One you are impressed, you want to see your favorite topic of Regular Expressions and how it is explained in the book. What will you do? I just peeped at you from behind and recorded what you did as below:
- You went to the Index page (it has total 25 pages). It is already sorted and hence you easily picked up Regular Expression that comes on page Number 17.
- Next, you noted down the number displayed next to it which is 407, 816, 1200-1220.
- Your first target is Page 407. You opened a page in the middle, the page is greater than 500.
- Then you moved to a somewhat lower page. But it still reads 310.
- Then you moved to a higher page. You are very lucky you exactly got page 407. [Yes man you got it. Otherwise I need to write more. OK?]
- That’s all, you started exploring what is written about Regular expression on that page, keeping in mind that you need to find page 816 also.
Here, the class column with distinct values 1,2,3..12 will store the clustered index columns value along with it. Say for example; Let us take only class value of 1. The Index goes like this:
1: 100, 104, 105
So here, you can easily get all the records that have value for class = 1.

3 comments:
It is a long instruction but worth reading. thank
Wow, incгedible blоg layout! Нοw long haѵe you been blogging for?
you make blogging look easy. The overall look
οf your site iѕ wonderful, let alоne the content!
my web site > ενοικιαζόμενες γκαρσονίερες ξάνθη
Thanks a lot...keep visiting!!!
Post a Comment